1. The Problem
Large language models generate fluent answers — but medical domains demand verifiable grounding, citation-backed claims, controlled hallucination behavior, and transparent evaluation.
The objective was not just to generate answers, but to build a measurable RAG system with structured evaluation loops.
2. System Architecture
Principles: separation of retrieval and generation; citation-first prompting; refusal when context is insufficient; evaluation-driven tuning loop.
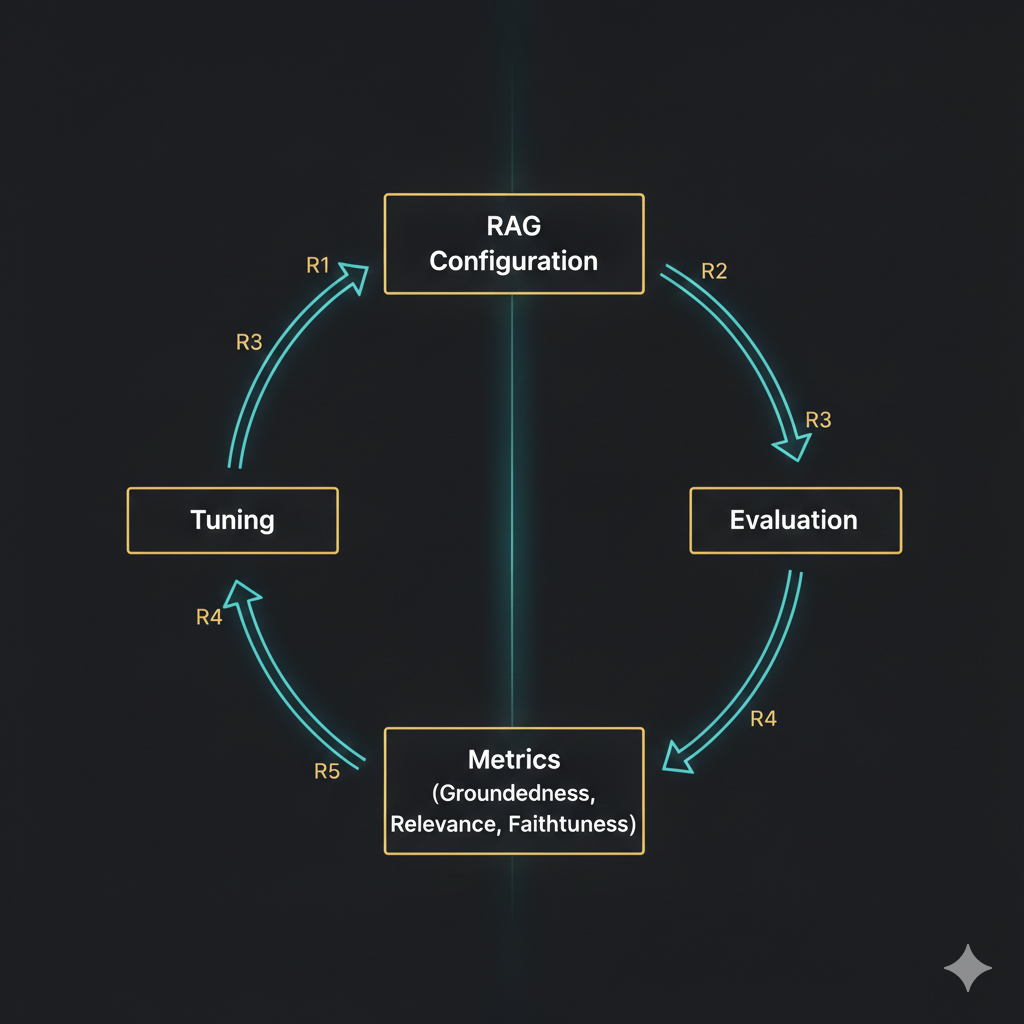
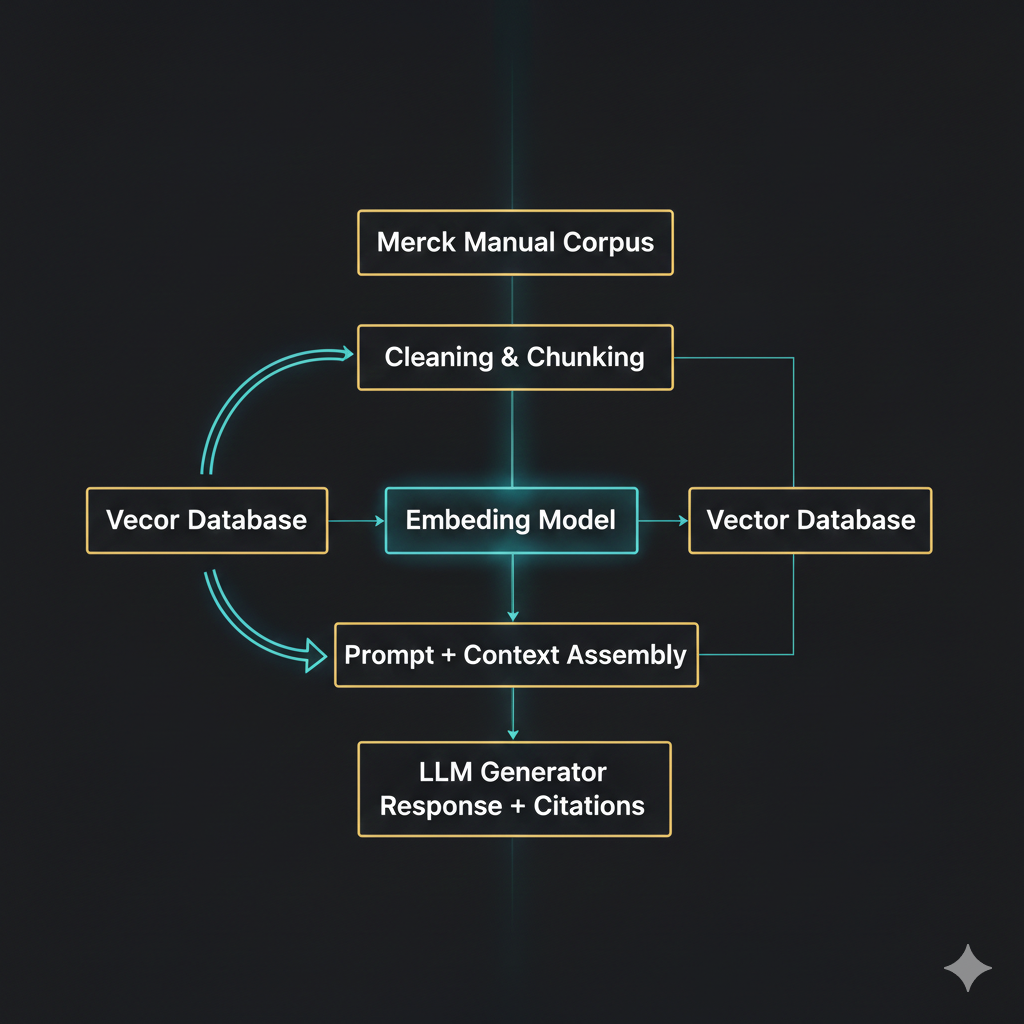
3. Iterative Tuning Framework (R1 → R5)
Instead of a static implementation, the system was tuned across multiple controlled iterations. Each version was evaluated systematically.
| Version | Change Focus | Improvement Objective |
|---|---|---|
| R1 | Baseline RAG | Establish baseline groundedness |
| R2 | Chunk size tuning | Improve contextual completeness |
| R3 | Retriever k optimization | Improve relevance precision |
| R4 | Prompt refinement | Reduce hallucinations |
| R5 | Final tuning | Maximize grounded + faithful outputs |

4. Evaluation Methodology
Unlike typical demos, this system includes structured evaluation across: groundedness, relevance, faithfulness, and consistency across runs.
Key insight: prompt engineering alone is insufficient — retrieval configuration materially impacts hallucination control.
5. Example Query Flow
6. Technical Stack
LLM: Mistral-7B-Instruct (inference optimized)
Embeddings: sentence-transformers
Vector Store: ChromaDB
Framework: LangChain
Runtime: Google Colab / Local GPU
Evaluation Loop: custom evaluation harness
7. Conclusion
This project demonstrates how Retrieval-Augmented Generation should be built: not as a demo, but as an evaluated, measurable, architected system.
Interested in safety-first RAG systems?
Let’s build domain assistants where trust is non-negotiable.